Google Python Automation Certification - Week 4
Data Type
String, List, Dictionary
1. What is String?
Data Type in Python.
= Empty String
= Using + sign is Concatenating(사슬같이 잇다, 연결시키다)
= len(pet) = number of character
So it is very important to know how to use them.
String을 잘 쓰려면, String에 어떤 옵션 들이 있는지 잘 알아야됨, 지금부터 그 옵션을 한번 보자
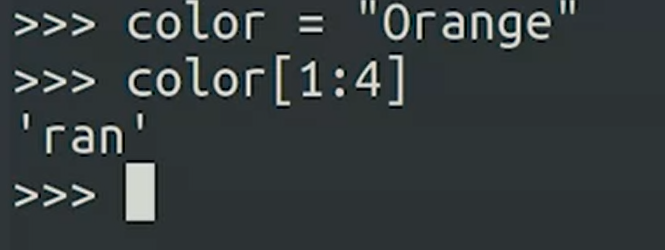
String Indexing


Negative Indexing = String 뒤에서부터 인덱스 프린트 하는거
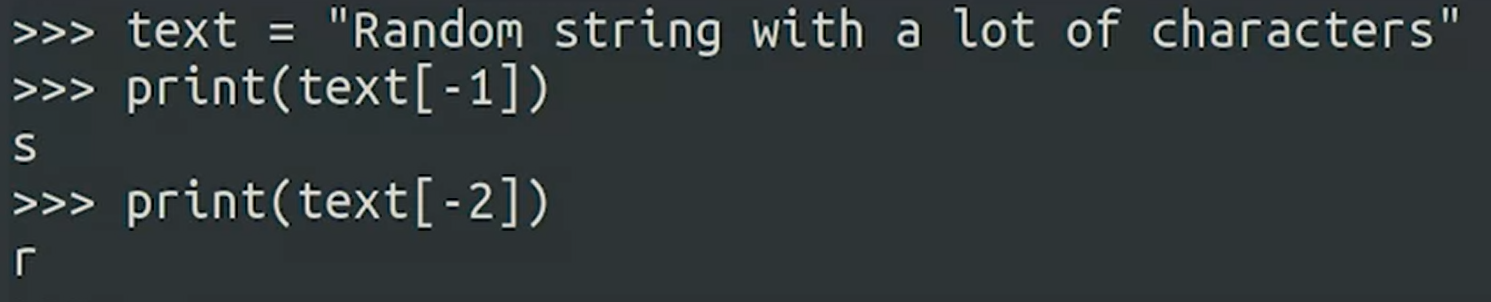

그래서 if not message 거나 message 스트링 비교 했을때 조건이 맞다면 True, 주고 empty인거 보면 False주는 게
if not message or message[0] == message[-1]로 되는거네, 시발
좆 같은 2분짜리 강의로 이해하려고 15분째 코딩하고 있네 시발 병신 고한길





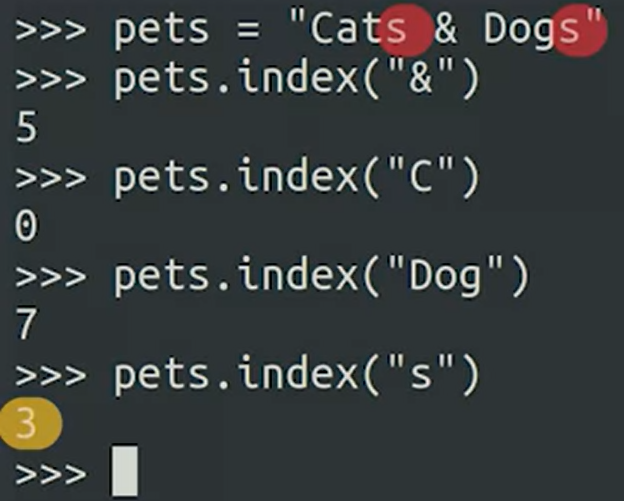
꼭 Bracket으로 써야함, value.index("Pet") 이런식으로
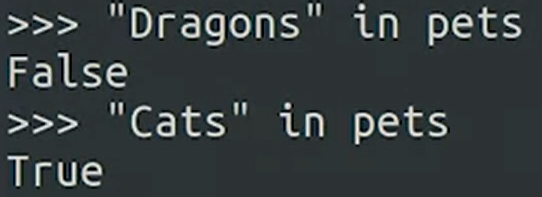
자! 이제 예를 들어보자,
만약 회사 URL이 바뀌어서 old email -> new email로 바꾸고 싶다? == String modification이 필요한 상황임

def replace_domain(email, old_domain, new_domain): #3개의 parameter를 가진 function을 만들자
if "@" + old_domain in email: # 만약 @dymos.com 이 email 안에 있는지 확인을 하고 만약 있으면
index = email.index("@" + old_domain) #옛날 도메인 index 시작 번호를 가꼬와서 email.index("") == index 넘버 체크하는 function 새로운 index value에다가 넣고
new_email = email[:index] + "@" + new_domain #새로운 new_email 벨류에다가 아까만든 index 번호 앞꺼, 즉 email ID만 가져온다음 + "@" + new_domain 값넣어주고
return new_email #해줘서 old email -> new email로 바뀌는 fuction 완성
return email #, 만약 없으면 그냥 email return


Strip == Srounding space 없애는거 , Tab, inline charactor
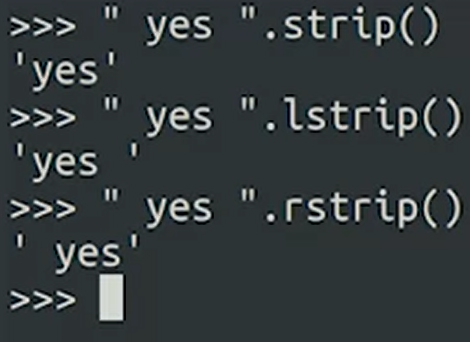







like "this is a string".upper(). This would return the string "THIS IS A STRING"
이렇게 스트링 뒤에 사용 가능 하니까 word[0].upper() 붙여서 쓴거구나 ..
format Method


return 에 print function 쓰면 에러남..

: == 필드네임
.2f == float 넘버로, 2 digit으로 표시하겠다

>3 == 3개의 space를 가지겠다
>6 == 6개의 space를 가지겠다
아~ 스트링 뒤에 더 옵션을 붙이기위해서 : 라는 기준점을 잡은거구나! 즉 {}이거랑 같은 표식이네 !!
String Cheet Sheet
String operations
- len(string) Returns the length of the string
- for character in string Iterates over each character in the string
- if substring in string Checks whether the substring is part of the string
- string[i] Accesses the character at index i of the string, starting at zero
- string[i:j] Accesses the substring starting at index i, ending at index j-1. If i is omitted, it's 0 by default. If j is omitted, it's len(string) by default.
String methods
- string.lower() / string.upper() Returns a copy of the string with all lower / upper case characters
- string.lstrip() / string.rstrip() / string.strip() Returns a copy of the string without left / right / left or right whitespace
- string.count(substring) Returns the number of times substring is present in the string
- string.isnumeric() Returns True if there are only numeric characters in the string. If not, returns False.
- string.isalpha() Returns True if there are only alphabetic characters in the string. If not, returns False.
- string.split() / string.split(delimiter) Returns a list of substrings that were separated by whitespace / delimiter
- string.replace(old, new) Returns a new string where all occurrences of old have been replaced by new.
- delimiter.join(list of strings) Returns a new string with all the strings joined by the delimiter

Formatting expressions
ExprMeaningExample
| {:d} | integer value | '{:d}'.format(10.5) → '10' |
| {:.2f} | floating point with that many decimals | '{:.2f}'.format(0.5) → '0.50' |
| {:.2s} | string with that many characters | '{:.2s}'.format('Python') → 'Py' |
| {:<6s} | string aligned to the left that many spaces | '{:<6s}'.format('Py') → 'Py ' |
| {:>6s} | string aligned to the right that many spaces | '{:>6s}'.format('Py') → ' Py' |
| {:^6s} | string centered in that many spaces | '{:^6s}'.format('Py') → ' Py ' |
List == []
len() function 쓰면 list안에 element 몇개 있는지 확인 가능.
in 쓰면, Boolean으로 list안의 값 확인 가능

index 넘는거 프린트 하려고 하면 index error나옴
List는 Mutable 하다
append method = 리스트 끝에 add하는거
insert = 리스트 위치 잡아서 거기다가 추가 하는거
remove = 리스트에서 element 지우는거 , 없는 element지우려고 하면 에러남
pop == remove하고 뭐가 remove됬는지 보여줌
fruit[x] = x자리에 element 수정

i = 0 나누기 2 해가지고, 짝수배열로 리스트 값 append시키게 해서 해결
파이썬 데이터 타입



[] 대신 () 이거 씀
fullname = ('Grace' , 'M' , 'Hopper')

function return 할때 Tuple로 return 함
튜플 데이터 타입일 경우에, index order를 신경 써야함
Unpack = 튜플 각각 값을 다른 변수로 저장해서 unpack할수있음 - 다른 3 seperated value
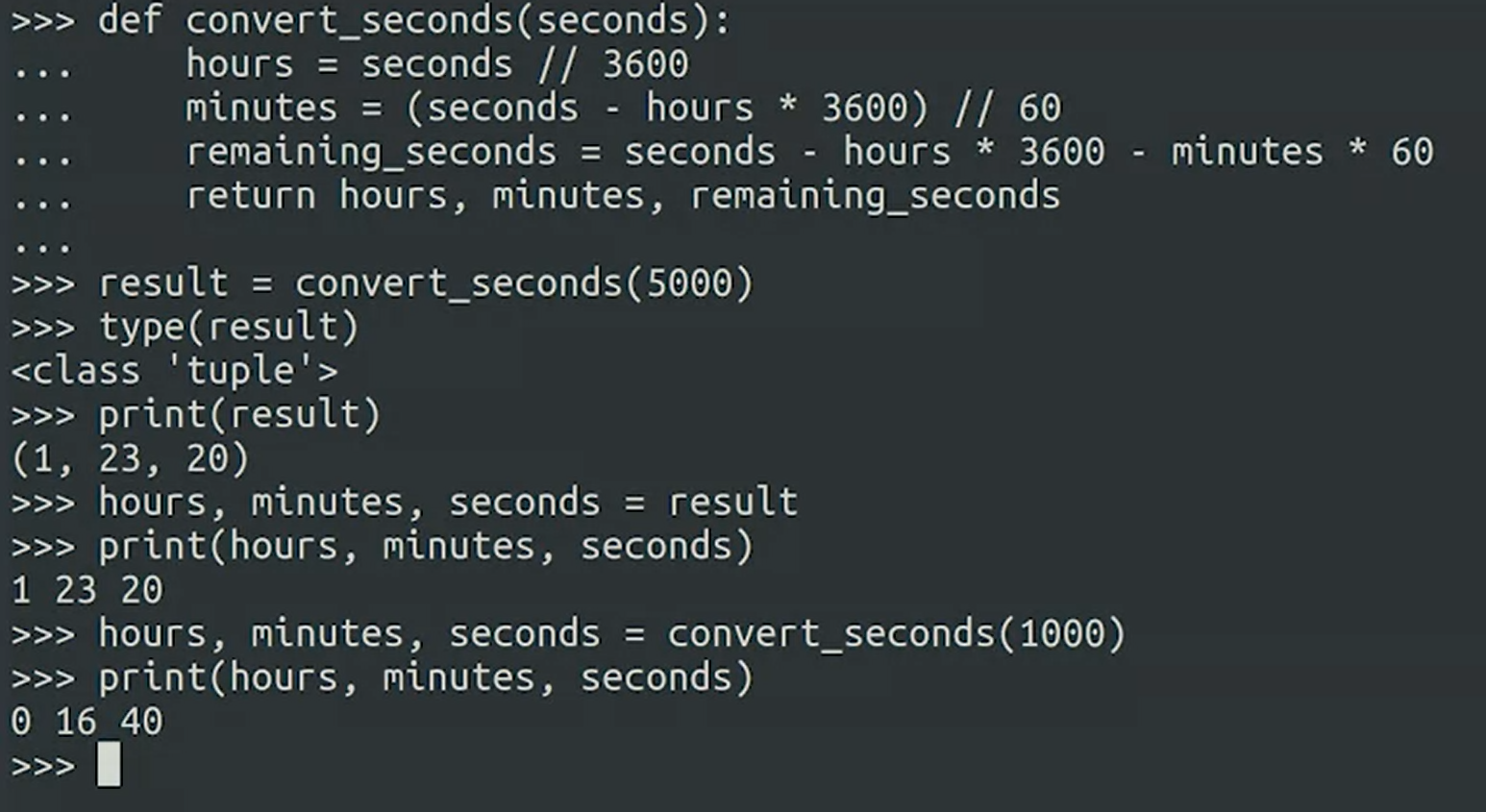
Tuples can be useful when we need to ensure that an element is in a certain position and will not change.
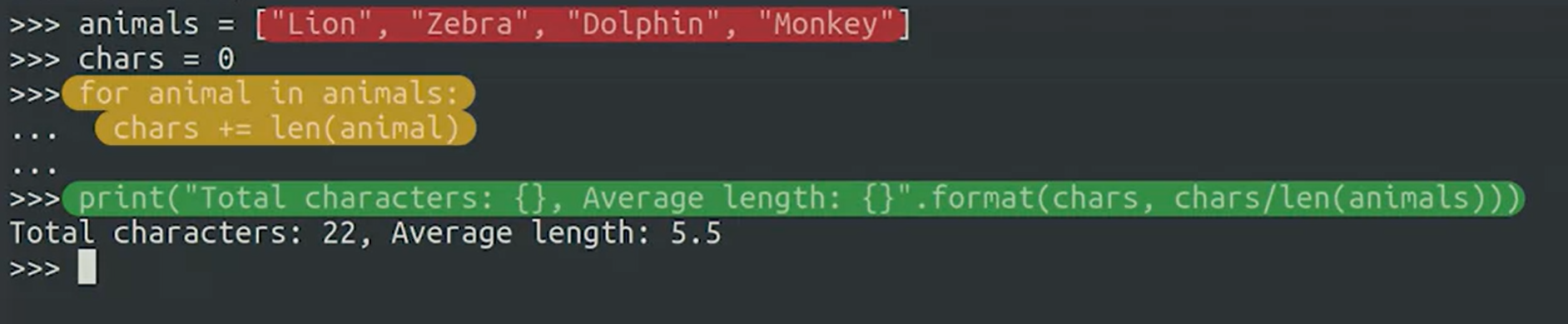

Enumerate method는
파이썬의 내장된 기능으로써 리스트 인덱스 요소를 함께 출력할때 사용한다
이렇게 enumerate 쓰면 인덱스 넘버랑 같이 출력 되게 할때 쓰는 기능
요소개수가 많아질수록 편리하게 사용가능
보통 반복문에서 사용 많이함
0 ('coke', 1000)
1 ('sprite', 1000)
2 ('vita 500', 800)
3 ('cocoparm', 700)
4 ('Water', 600)
반복문 쓸때, 변수 2개주고 in 다음 enumerate function 에다가 list 값 넣어주면 저런식으로 출력이 됨
즉 인덱스 번호랑 같이 출력 하고자할때 쓰는거
간단한 반복문 으로 써도 되긴 함
보통 이렇게 e라는 변수 주고, 반복 될때마다 1씩 늘어나도록 하는 식으로 사용함
차이점이 있다면 코드 두줄 차이인데, 추후에 프로그램을 짜다보면 리스트에 들어있는것도 많아지고 하다보면 귀찮아짐 = 프로그램이 복잡해짐 , 인덱스 변호 몇번일때.. 뭐 이런거
이렇게 people이라는 parameter 변수에,리스트 값으로 넣어서 function 출력 가능
The enumerate() function takes a list as a parameter and returns a tuple for each element in the list.
List Comparison
List comprehension

이렇게 위에꺼랑 다르게 표현 가능
이렇게 같이 써가지고 값 출력 가능

Common sequence operations
- len(sequence) Returns the length of the sequence
- for element in sequence Iterates over each element in the sequence
- if element in sequence Checks whether the element is part of the sequence
- sequence[i] Accesses the element at index i of the sequence, starting at zero
- sequence[i:j] Accesses a slice starting at index i, ending at index j-1. If i is omitted, it's 0 by default. If j is omitted, it's len(sequence) by default.
- for index, element in enumerate(sequence) Iterates over both the indexes and the elements in the sequence at the same time
Check out the official documentation for sequence operations.
List-specific operations and methods
- list[i] = x Replaces the element at index i with x
- list.append(x) Inserts x at the end of the list
- list.insert(i, x) Inserts x at index i
- list.pop(i) Returns the element a index i, also removing it from the list. If i is omitted, the last element is returned and removed.
- list.remove(x) Removes the first occurrence of x in the list
- list.sort() Sorts the items in the list
- list.reverse() Reverses the order of items of the list
- list.clear() Removes all the items of the list
- list.copy() Creates a copy of the list
- list.extend(other_list) Appends all the elements of other_list at the end of list
Dictionary
PS C:\Users\Wayne Ko\Desktop\Python> & "C:/Users/Wayne Ko/AppData/Local/Programs/Python/Python310/python.exe" "c:/Users/Wayne Ko/Desktop/Python/Google_Python/First.py"
14
True
True
{'jpg': 10, 'txt': 14, 'csv': 2, 'py': 23, 'cfg': 8}
{'jpg': 1, 'txt': 14, 'csv': 2, 'py': 23, 'cfg': 8}
{'jpg': 1, 'txt': 14, 'csv': 2, 'py': 23}
jpg
txt
csv
py이렇게 하면Key 프린트함
There are 10 files with the . jpg
There are 14 files with the . txt
There are 2 files with the . csv
There are 23 files with the . py
이렇게 item () Method 써가지고 Key랑 Value 둘다 출력가능
dict_keys(['jpg', 'txt', 'csv', 'py'])
dict_values([10, 14, 2, 23])



Dictionary Methods Cheat Sheet
Definition
x = {key1:value1, key2:value2}
Operations
- len(dictionary) - Returns the number of items in the dictionary
- for key in dictionary - Iterates over each key in the dictionary
- for key, value in dictionary.items() - Iterates over each key,value pair in the dictionary
- if key in dictionary - Checks whether the key is in the dictionary
- dictionary[key] - Accesses the item with key key of the dictionary
- dictionary[key] = value - Sets the value associated with key
- del dictionary[key] - Removes the item with key key from the dictionary
Methods
- dict.get(key, default) - Returns the element corresponding to key, or default if it's not present
- dict.keys() - Returns a sequence containing the keys in the dictionary
- dict.values() - Returns a sequence containing the values in the dictionary
- dict.update(other_dictionary) - Updates the dictionary with the items coming from the other dictionary. Existing entries will be replaced; new entries will be added.
- dict.clear() - Removes all the items of the dictionary
python dictionary 에서
item method = 딕셔너리값 item으로 묶어주는거 ()
value method = 딕셔너리안의 키값 만 묶어주는거 ()
comprehension = 이해력
horn = 뿔
fin = 지느러미
tentacle = 촉수
enumerate == 열거하다
corresponding = 해당하는, 상응하는
palindrome = 뒤에서 읽으나 앞에서 읽으나 똑같은구문